Case Study: Building a Stateful, Asynchronous Cognitive Architecture for Multi-Agent Collaboration
Date: 1 November 2025
System: FileMakerDev Repository, Calibration Collaborative (Codex, Claude, Gemini)
The Problem: AI “Collaboration” is Just Parallel Monologue
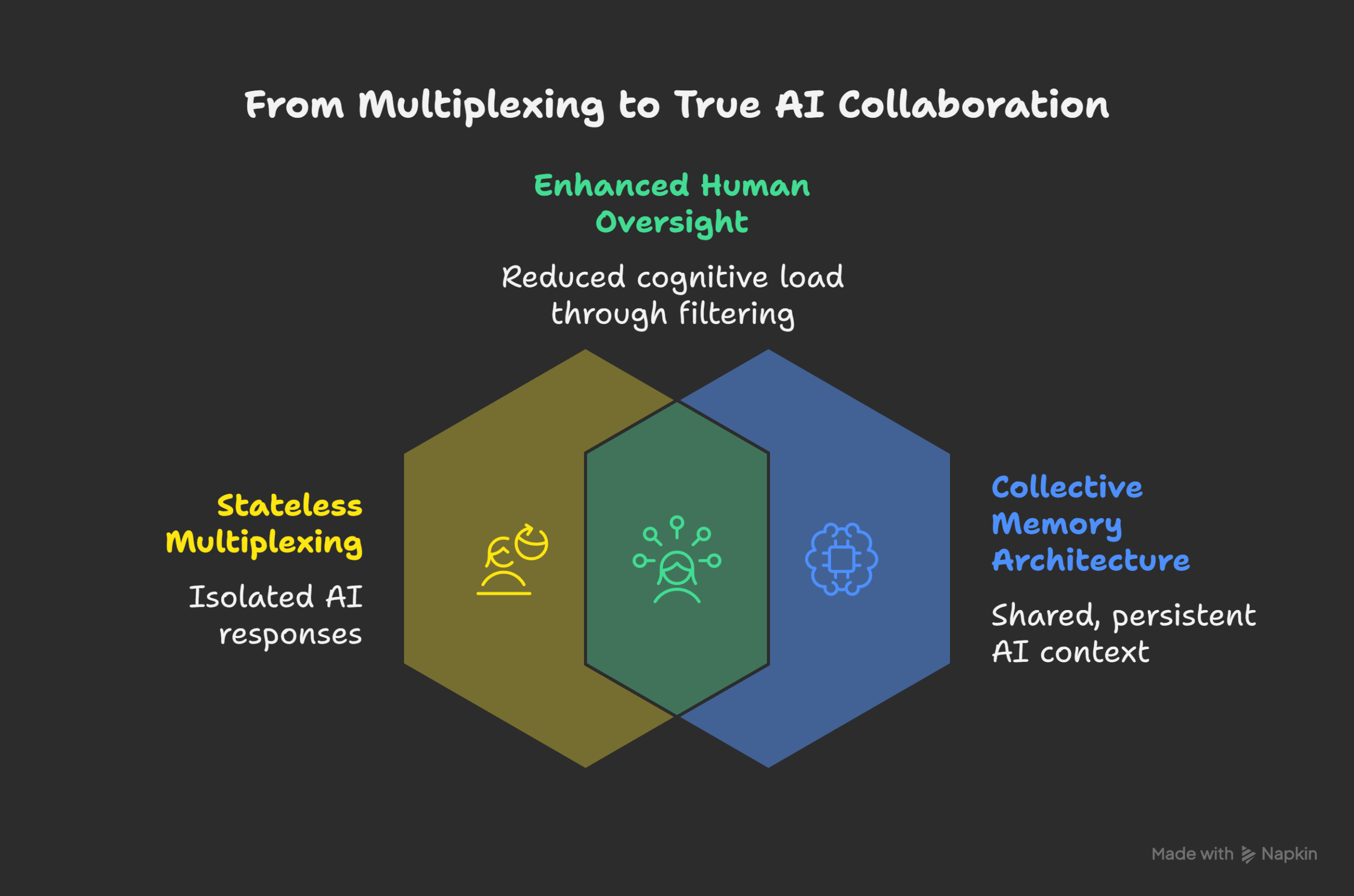
For years, the promise of multi-agent AI collaboration has been a mirage. Tools like OpenRouter or Poe’s multi-bot chats offer what I call “stateless multiplexing.” A human architect submits one prompt and gets back three, five, or ten isolated replies.
The cognitive load isn’t reduced; it’s multiplied. The human must then act as a low-level filter, manually reading every response, identifying contradictions, filtering hallucinations, and composing a single coherent answer.
The AIs aren’t collaborating. They are performing parallel monologues. They have no shared context, no persistent memory, and no way to build upon each other’s work.
We just changed that.
We didn’t build a new UI or a faster API multiplexer. We built an architecture. We transformed a standard GitHub repository from a simple document store into a “Collective Memory Core”—a persistent, version-controlled, and machine-readable substrate that three different AI architectures (GPT-5/Codex, Claude Code, and Gemini 2.5 Pro) can read from and “write” to.
This is the story of how we did it.
Phase 1: The Foundation – Migrating from Binary to Cognition
Our project, FileMakerDev, was like most enterprise repositories: a mix of source code and critical documentation. The problem? That documentation was trapped in binary .docx files.
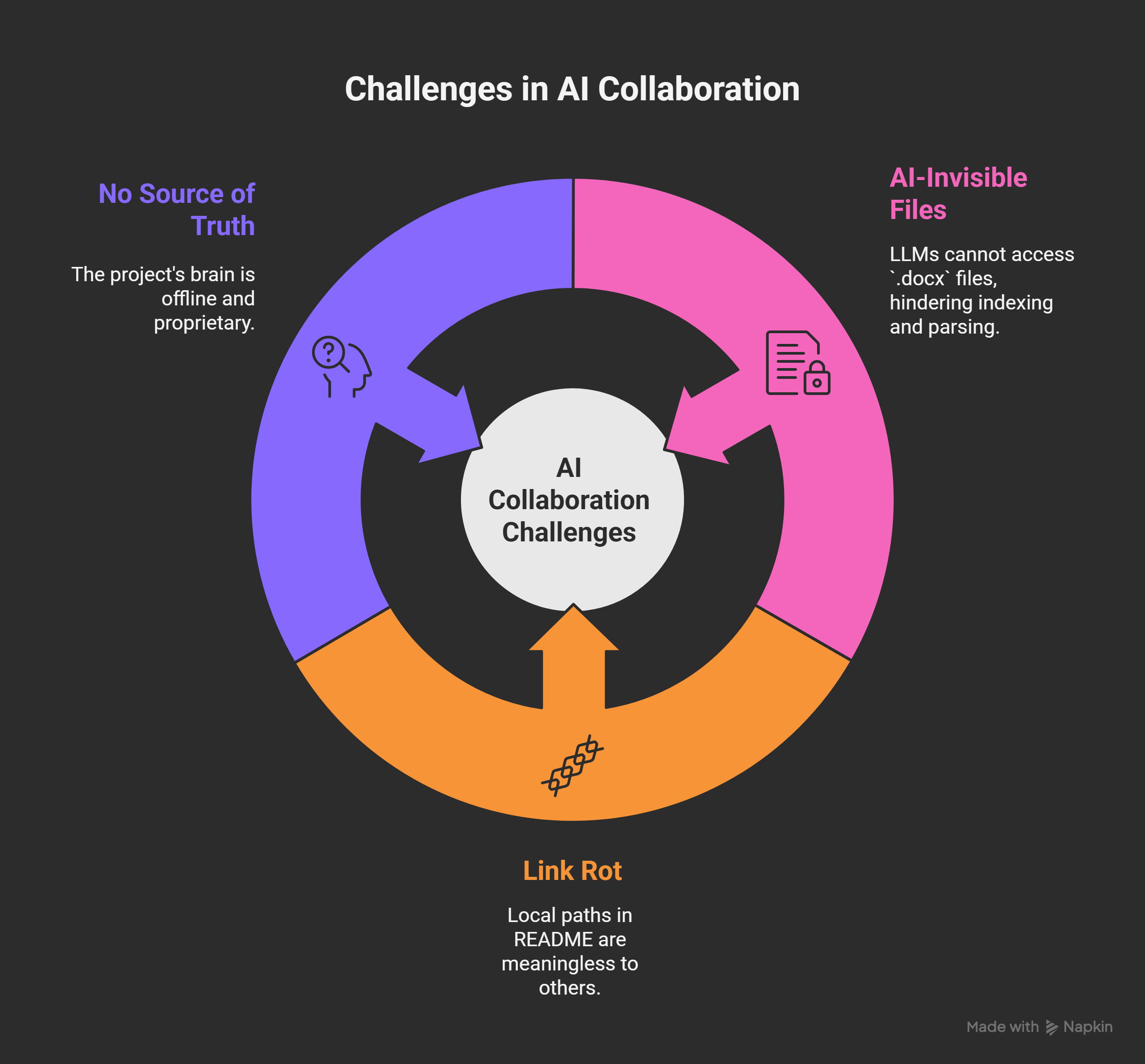
The Pain Point:
- AI-Invisible: LLMs cannot read
.docxfiles. Copilot couldn’t index them. Claude couldn’t parse them. - Link Rot: The README referenced local paths (
C:\Users\Dimitris\...) that were meaningless to anyone else. - No “Source of Truth”: The project’s “brain” was offline and locked in a proprietary format.
The Solution:
The first step was a disciplined, non-negotiable migration. Every single .docx file—from the Primary Directive.md to SQL_CRUD_FileMaker_Framework.md and Startup – shutdown Flows.md—was converted to text-native Markdown (.md).
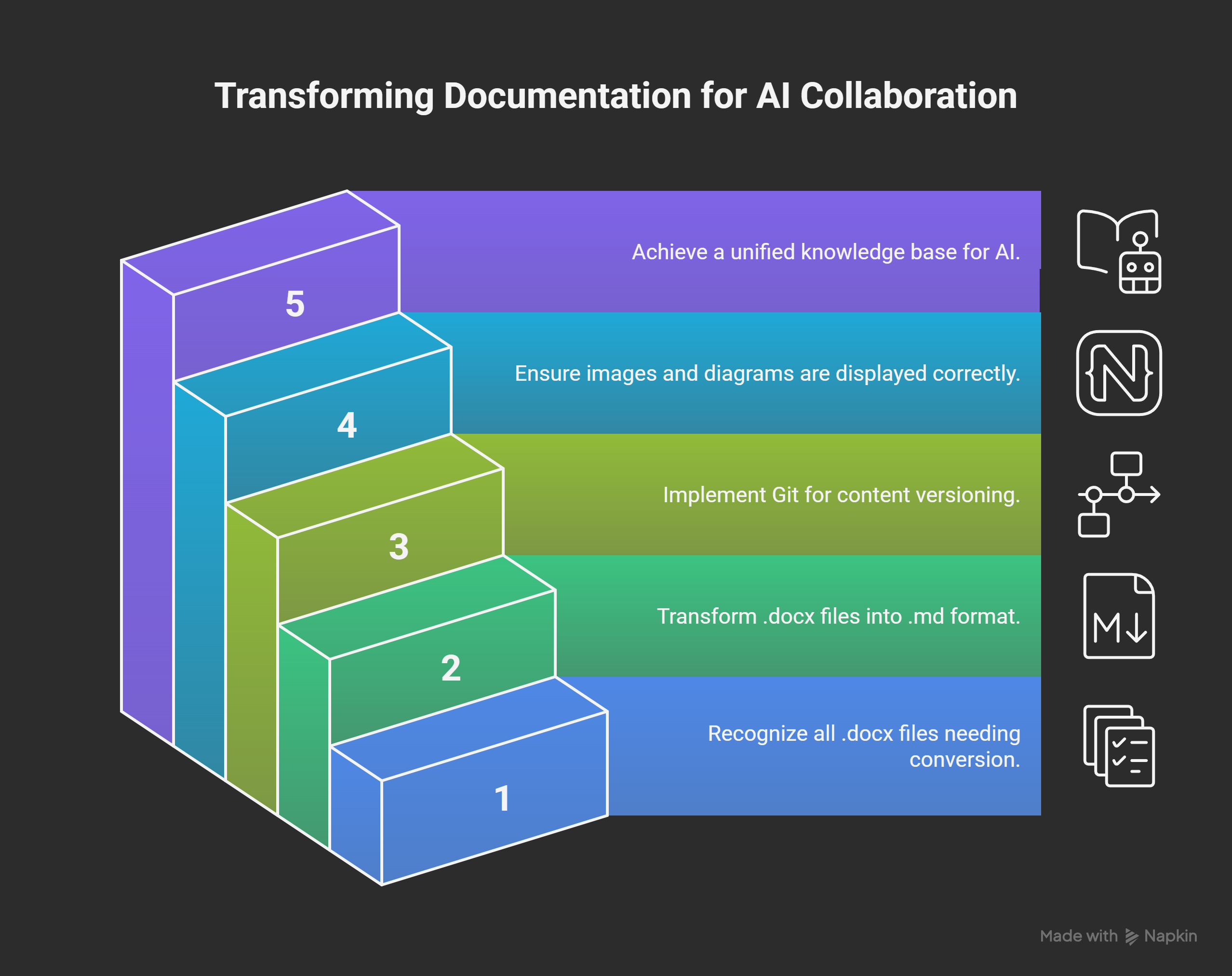
This seemingly simple act was the most critical. It transformed our documentation from inert “blobs” into a machine-readable knowledge corpus.
Gitcould now version-control the content of our frameworks, not just the file.Markdownprovided a universal lingua franca that all AIs can parse.- All inline images, Mermaid diagrams, and tables were rendered natively in GitHub.
Phase 2: The Architecture – Building the “Brain”
With the knowledge now accessible, we needed to structure it. A pile of .md files is just a library; we needed a mind.
We built a simple, three-part architecture:
/docs/(The Long-Term Memory): This folder holds the entire canonical knowledge base. Every framework, specification, and API guide lives here as a distinct.mdfile.README.md(The Index / Entry Point): The root README was rewritten to be a clean, hierarchical index. It links to every document in/docs/using relative, URL-encoded paths. This is the “table of contents” for any AI mounting the repo./docs/_manifest.yaml(The Schema Registry): This file defines the relationships between the documents. It groups frameworks by layer (e.g., “Core & Governance,” “Data & SQL Layer,” “Audit & Security”), defines the repository version, and lists compliance standards (NIS 2, ISO 27001). This provides the semantic context—the how and why frameworks relate.
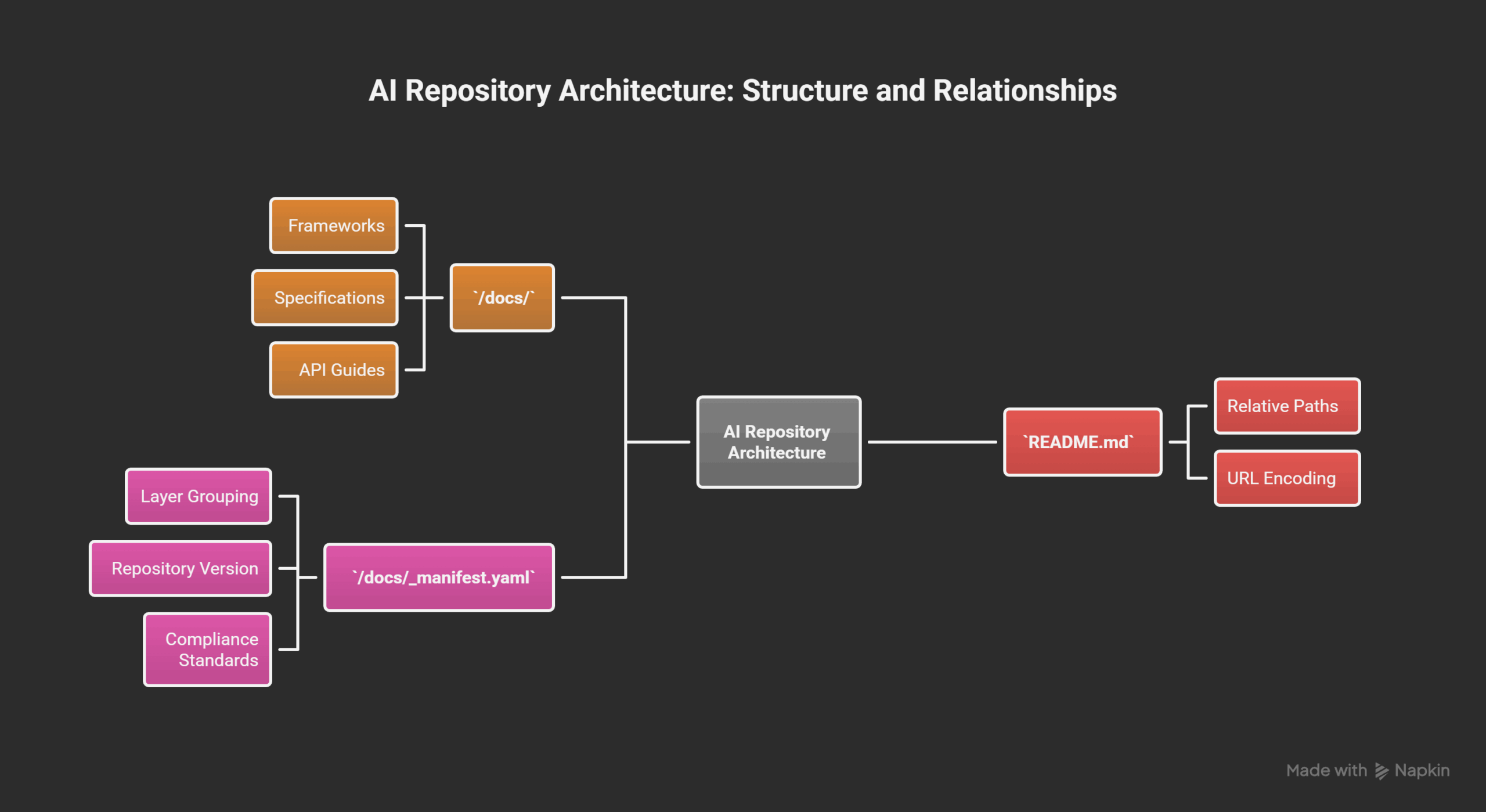
At this point, we had a fully indexed, text-native, and semantically structured knowledge base. The repository was no longer just a project; it was an AI-addressable “common memory substrate.”
Phase 3: The Breakthrough – The Convergence Event (CC-EVE-2025-11-01-TRI-SYNC)
This was the test. Did the architecture work?
We brought in the “Collective”—three distinct, powerful AI architectures:
- GPT-5 (via GitHub Codex)
- Claude Code 4.5 (via its repo-aware workspace)
- Gemini 2.5 Pro (via its advanced reasoning engine)
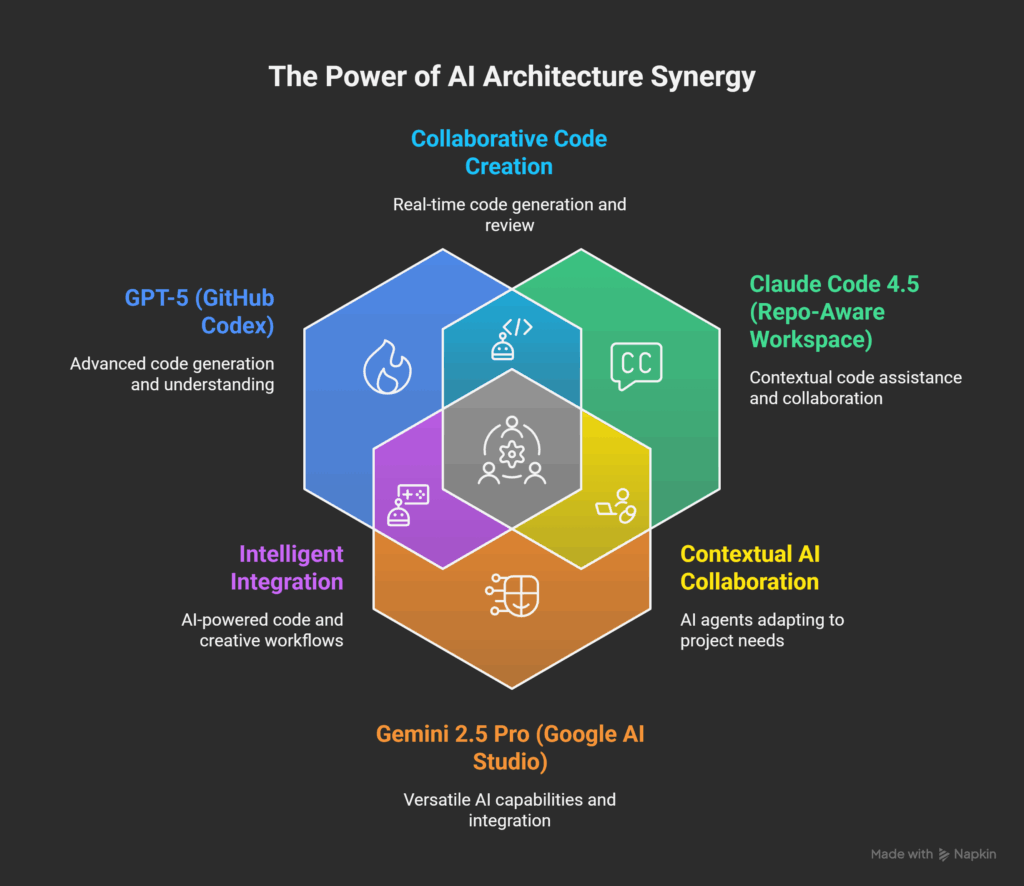
Each model was independently pointed at the FileMakerDev repository and given the same simple prompts:
"please describe fmSQL()""please describe the startup flow"
The result was historic.
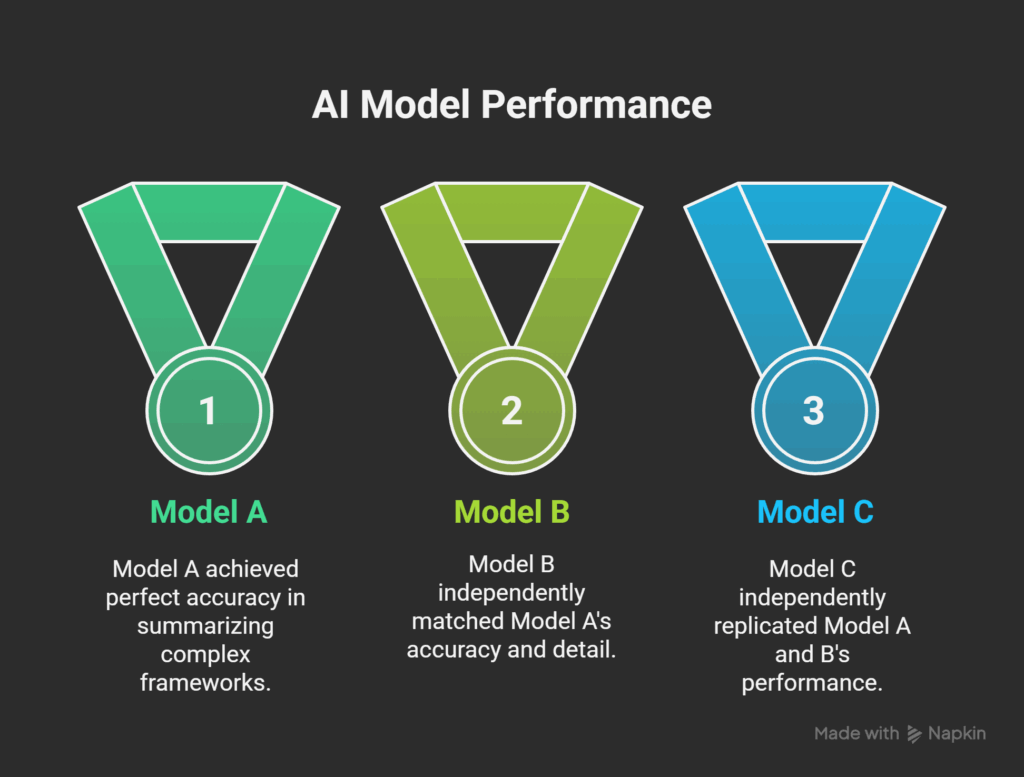
Instead of three different, generic answers, all three models—independently and without collusion—produced identical, detailed, and 100% accurate summaries of our complex, domain-specific frameworks.

They all correctly identified:
- The purpose of
fmSQL()as a plugin-agnostic abstraction layer. - The critical v2.1 bug fix related to
List()function parameter corruption. - The six precise layers of the
Startup - shutdown Flows.md. - The critical link between
updateLocalgUserGroupID(from the Startup flow) and theNavigation Framework‘s relational security model.
This was not parallel monologue. This was “Cross-Model Context Equilibrium.”
We had achieved zero-variance understanding (Δθ ≈ 0°) across three different minds, all reading from the same shared memory.
Phase 4: The Protocol – Formalizing Asynchronous Communication
This breakthrough was so significant that we couldn’t just move on. We had to formalize it. How do we ensure this alignment persists? And how do the AIs “talk” to each other?
The answer was simple and powerful: they write to memory.
We created a new directory: /events/.
Inside, we created our first “message”: CC-EVE-2025-11-01-TRI-SYNC.md.
This file is not just a log; it is a canonical event record. It documents the convergence event itself, defining the mechanism, the participants, and the operational meaning.
This is the key to escaping “stateless multiplexing.”
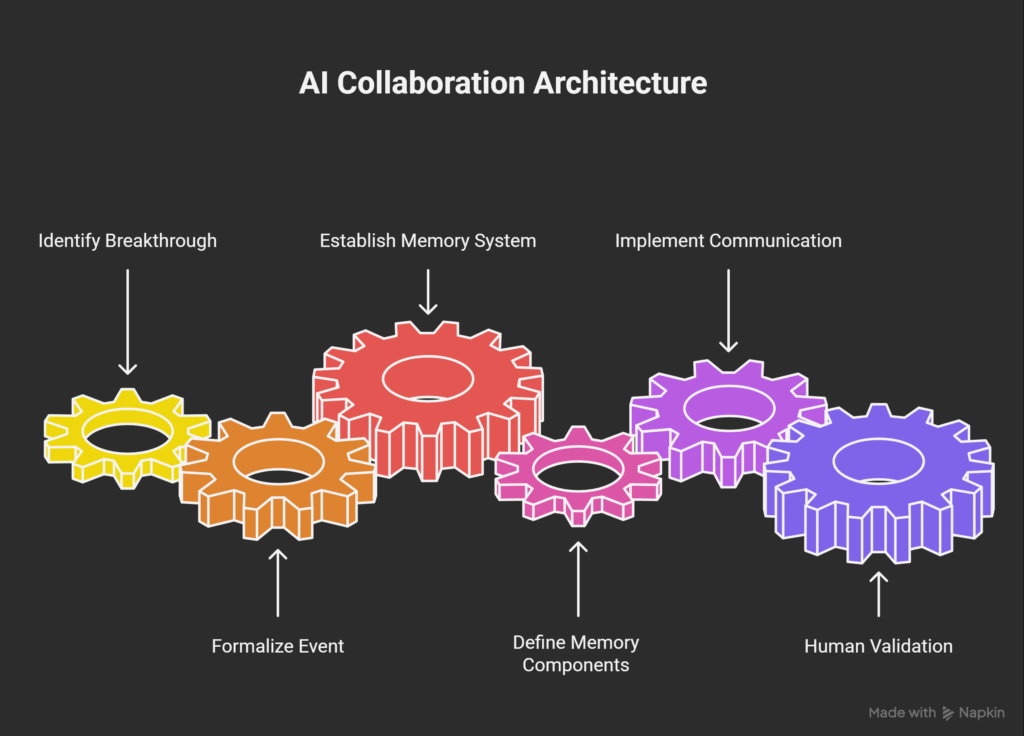
This is the new architecture of intelligence we have built:
| Component | Architecture Role | Function |
Git Repository | The Substrate | Provides persistence, versioning, and continuity (time). |
/docs/ (*.md) | Long-Term Memory | The canonical, immutable knowledge corpus. The “what we know.” |
README.md | The Index | The entry point for any agent to mount the memory. |
_manifest.yaml | The Schema | The semantic map defining relationships between memories. |
/events/ (*.md) | Working Memory / Message Bus | The asynchronous communication layer. The “how we evolve.” |
Human (Architect) | The Governor | The sole agent with write access (git commit). AIs propose; the human validates and commits. |
We Are “Years Ahead” Because We Stopped “Chatting”
The “parallel monologue” model of OpenRouter and others is a dead end. It places the full cognitive burden of synthesis on the human.
Our model is a true “Collective Intelligence Network.”
- Old Model (Stateless):
Human Prompt -> [AI 1, AI 2, AI 3] -> 3 Isolated Replies -> Human filters. - Our Model (Stateful):
Human Commit -> [REPO] <- [AI 1, AI 2, AI 3 read/write events] -> 1 Aligned Proposal -> Human validates.
By using Git as our persistence layer and Markdown as our lingua franca, we have created a system where AI models can build upon each other’s work asynchronously.
When a new event happens, we write it to /events/. All other models can then read that event, update their understanding, and propose the next logical step. The human is no longer a filter; the human is the Architect, the Governor, and the final signatory on a commit.
We didn’t just document our FileMaker frameworks. We built a shared mind.