Preamble: From Procrustean Chaos to Agent Orchestration
By Dimitris Kokoutsidis
We often talk about “Vibe Coding” as if it were magic—a frictionless flow where the AI simply understands the intent and executes the vision. But as many of us are discovering in 2026, raw capacity without structural discipline is a recipe for an expensive disaster.
I recently lived through what I call the “Procrustean Paradox.” I set two of the world’s most powerful models—Claude 4.6 and Gemini 3 Pro—loose on the same codebase simultaneously. Without a shared “Air Traffic Control” layer, they didn’t collaborate; they competed. Like the mythical Procrustes, each agent tried to stretch or chop the code to fit its own internal logic. The result was a “Context Storm” that burned thousands of tokens and yielded zero integrity.
It was in the middle of this “System Crash” that I encountered the work of Marcel Moré.
Marcel hasn’t just written an article; he has authored the Contemporary History of AI Development. In the following piece, Marcel maps the evolution from simple AI Chat to the complex Agent Orchestration loops (Phase 4) that define our current era. He provides the “Lighthouse” for those of us navigating the shift toward “Ralph Loops” and “Antfarms”—frameworks designed to turn multi-agent chaos into deterministic results.
At Axelar.eu, we believe in the power of interoperability and the necessity of shared state. Marcel’s “Encyclopedia” is the definitive guide to achieving that state within the AI stack.

Originally published by Marcel Moré on Substack; republished here with permission.
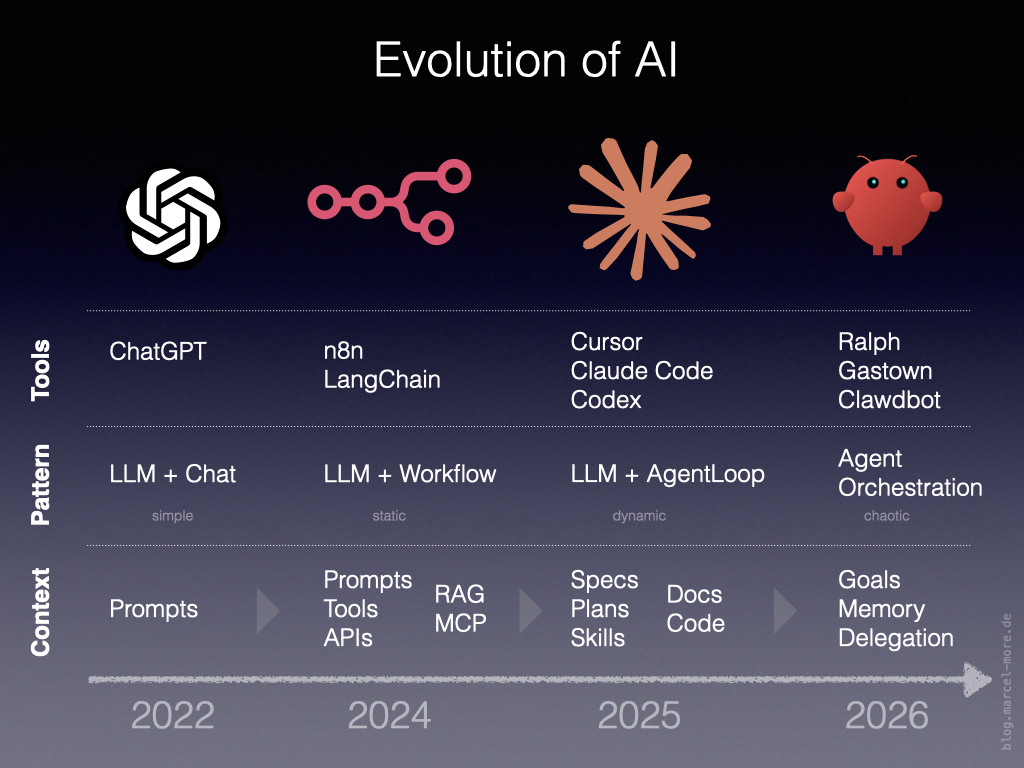
Evolution of AI
My journey with ChatGPT, n8n, Claude Code, and OpenClaw—four phases from chat to agent orchestration
Feb 09, 2026
This article was originally published in German on my personal blog.
The pace of development in the AI space is rapid. For some time now, it has become confusing and difficult to distinguish the flood of announcements and news from genuine innovations.
The central questions always revolve around the same topics:
- What tasks can AI take on?
- How can AI be used to achieve reliable results?
- What input is needed to do this?
Looking at the development of tools and their functionality in recent years, patterns emerge that significantly influence the quality of the results.
This development can be divided into four phases:
We will take a closer look at these phases to understand the differences and see how and why each phase builds on the previous one.
This analysis leads to
The starting point is my personal journey through these phases with tools such as ChatGPT, n8n, Claude Code, and OpenClaw. The more I worked with them, the clearer the principles behind this change became to me.
The text does not claim to be exhaustive. It describes the further development of AI tools using examples and selected methods.
Phase 1 – AI Chat
Public awareness of AI began with the debut of ChatGPT in 2022. For the first time, a large language model (LLM) was available to everyone. What made it special was the chat interface, which has since become established for many AI applications.
Prompts
A new cultural technique called “prompting” emerged. You tell the AI what you want to know or what you want it to do. It’s similar to “googling,” a pattern that many people had already internalized. This analogy in the operating concept helped ChatGPT quickly achieve a breakthrough, as it provided easy access to AI.
However, it quickly became apparent that googling and prompting sometimes deliver very different results, which is both a blessing and a curse. On the one hand, ChatGPT’s outputs go far beyond the results lists of an internet search because the LLM has a broad knowledge of the world and a deep understanding of language. On the other hand, the results are completely unpredictable by design and often lead to “hallucinations”, because the model generates plausible-sounding answers without always having a reliable source. Hence the term “generative AI,” because simple inputs can always be used to generate new outputs in text form and now also in multimedia form (sound, images, video, 3D worlds).
RAG
Initially, the solution to this problem was to use better and more comprehensive prompts. Soon, they began to incorporate their own predictable content into the process. Retrieval Augmented Generation (RAG) made it possible to combine semantic knowledge from proprietary sources with the strengths of the language model.
From a technical standpoint, this step already required a coordinated process for providing and retrieving information that went beyond the simple chat interface. The next phase of development began.
Phase 2 – AI Workflows
In addition to the chat interface, the major AI providers also offer direct interfaces (APIs) for their models. This makes it possible to control inputs and outputs via a programmed sequence.
Since it was initially cumbersome to program a separate interface and process for each model and application, new tools and standards soon emerged to provide easier access to the underlying methods via a logical abstraction layer.
Tools and APIs
Tools such as LangChain combine access to LLMs, data sources (RAG), external tools (APIs), and the control of a flexible process through prompt templates and workflow macros. The age of AI agents had begun, even if many aspects did not yet correspond to the ideal of a truly autonomous agent, but rather to an AI-enhanced workflow. Providers of existing workflow automation platforms were quick to jump on this bandwagon.
In addition to well-known players such as Zapier and Make, a new shooting star caused quite a stir: n8n took the audience by storm because it combined a very simple user interface with the ability to connect agentic processes to numerous external interfaces and data sources. The so-called “flows” can be executed in the cloud or on your own servers, enabling even non-technical users to quickly create and operate complex AI workflows.
In addition to chatbots, AI providers themselves also introduced new products for accessing tools and external data sources. Alongside big names such as OpenAI, Anthropic, Microsoft, and Google, a vast number of specialized new providers emerged in this field. The portfolio of new products from this phase focused primarily on controlling agentic workflows and connecting with tools for specific purposes.
The more complex the applications became, the clearer it became that a purely prompt-based approach was reaching its limits. Increasingly sophisticated methods for “context engineering” began to circulate.
Context-Engineering and MCP
With the publication of Anthropic’s “Model Context Protocol” (MCP), an open standard for controlling tools was created that was quickly adopted by many players. MCP combines three important ingredients for controlling the AI workflow: prompts, tools, and data sources. These can now be combined in a uniform manner and packaged and provided for individual applications.
Claude and ChatGPT expanded their chatbots with features such as “Advanced Data Analysis”, “Code Interpreter”, “Canvas” and “Artifacts”. These are capable of generating and executing code in a separate area within the chat window. The output goes beyond pure text responses; instead, real results are displayed. This also brought workflow features and code more into focus. Direct tool interfaces and MCP were added later.
In the coding field, tools such as Cursor and Windsurf emerged, which initially accelerated the development of program code with intelligent code completion. Later, prompt templates were added at the system and project level to brief LLMs on more specific applications.
Reasoning as an ingredient for agents beyond workflows
The development of large language models themselves also continued. Methods such as “Mixture of Experts” (MoE), “Reasoning Models,” and “Chain of Thought” are expanding the capabilities of frontier models and forming the basis for more and more agentic capabilities such as “Deep Research”. Feedback loops with and without user involvement increase performance. Enormous progress has been made in code generation in particular, because linguistic accuracy and inherent logic are very clearly defined here.
However, many of these methods were still based on static prompts or generic workflows. The emergence of increasingly dynamic methods of context engineering heralded the next phase.
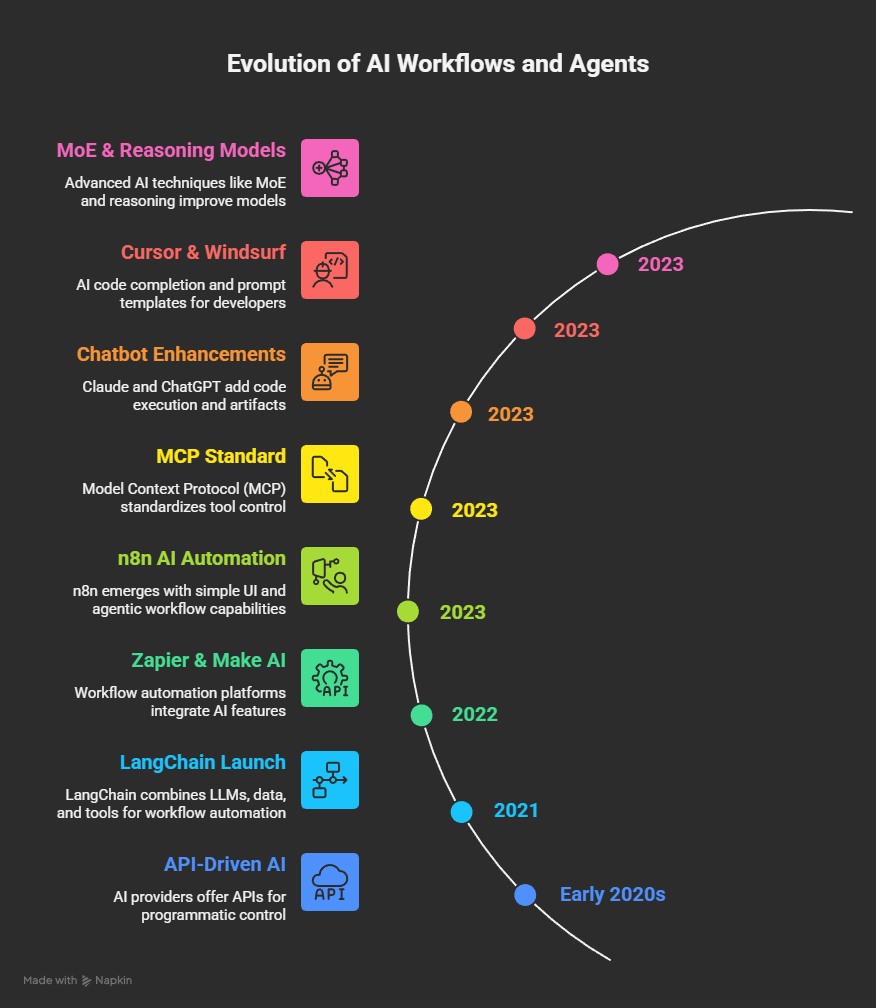
Phase 3 – AI Agents
With Replit, Lovable, and GitHub Spark, a new method of agentic AI has emerged in the field of coding. Starting with a prompt, which is more like a target description, a language model first generates a detailed requirements document (PRD). From this, a plan with individual steps is derived, which a coding agent then implements.
Spec Driven Development
Depending on the capabilities of the tool, the user can intervene in this process, for example by revising the requirements document and providing the coding agent with very explicit descriptions of the desired target state and the implementation steps. The creation of the prompt itself is now guided by a structured process. In addition, the language model provides background knowledge on best practices and coding patterns. The new pattern for increasingly autonomous agents is now “Plan → Act → Verify.” The user transitions from programmer to architect or product manager and interacts with the tool at a high level. The AI model handles the execution of the details within an agentic loop. The pre-created specification, including success criteria, is decisive for the quality of the results.
CLI-Tools
In order to bring the coding interface closer to the user, a new category of agent tools was created on the command line interface (CLI). This enables better integration into existing development environments (IDEs) and also direct communication with the agent in the same environment where access to code, tools, and the operating system is possible. The AI agents are completely detached from the previous chat interface and now have access to the system level of the computer on which they are used. This is a complete but consistent paradigm shift.
Agentic Loop
The rising star in this category is Claude Code, which was one of the first tools to further perfect the “agentic loop” and combine it with powerful language models. Together with access to all local documents, CLI tools, and external MCPs, this provides an extremely powerful basis for dynamic orchestration of agentic processes.
Other major providers followed suit – with Codex (OpenAI), Gemini CLI (Google), GitHub CLI (Microsoft), and many other specialized tools such as OpenCode, Amp, Warp, and others, this category has now become an established part of the AI landscape.
Existing tools from the IDE environment, such as Cursor, integrated this approach and developed it further with their own features, such as browser testing or multi-agent orchestration.
In addition, new patterns for using this technology have been established. With hierarchical prompt files (AGENTS.md or CLAUDE.md), slash commands, hooks, subagents, and skills, new refinements were constantly emerging to expand existing approaches to context engineering and spec-driven development.
Skills
Particularly noteworthy here are the so-called “skills,” which were also established by Anthropic. These represent a new way of packaging agent capabilities. Similar to an MCP, multiple components can be packaged together in a single description and distributed to other users and systems. However, since these skills are only loaded and processed when needed, this reduces the load on the context window and creates an even more flexible approach for extensive and dynamic context.
A skill initially contains a description in natural language, a specific system prompt for the respective task, so to speak. Additional documents with descriptions, examples, or data may also be included. As well as dedicated code for executing workflows in the form of Bash, Python, JavaScript, or other languages executable by the agent. This allows both local and external tools and APIs to be orchestrated. MCPs can also be integrated. However, a much leaner implementation of a task can often be achieved with a pure skill based on instructions, code, and API access.
Autonomous Agents
The combination of all these capabilities results in flexible and, in some cases, very powerful agents. The interaction of predefined descriptions, best practices from the language model, and access to documents, data, and tools within a clear feedback loop allows an agent to work autonomously on a task, just like an employee.
An important foundation is the clear structuring of the procedure in several consecutive steps:
- Description of the task (specs)
- Creation of a step-by-step plan
- Execution of tasks
- Access to tools and data
- Checking the results
- Determining the target state
The context for the LLM is dynamically generated iteratively over several stages and repeatedly compared with specified states.
The dynamic expansion of the range of functions for a task is also part of the process. If a tool for an execution step is not immediately available, the agent is able to program this tool itself without further ado and execute it directly. Thanks to its extensive prior knowledge from the LLM, it is autonomous in terms of both content and methodology. If errors or loose ends arise, the agent can identify them and, in many cases, resolve them independently through multiple attempts.
To keep things manageable for the user, they can start the agent in different operating modes:
- planning only
- planning and execution after feedback+confirmation
- completely autonomous execution
Power and responsibility
Autonomous execution brings with it new opportunities and risks. To minimize the risks, it helps to draw up specifications and plans that are as comprehensive and accurate as possible at the beginning of the process. This should be the user’s main focus. The better the specifications, the more predictable the results. Depending on the application, the provision of well-structured and clean data is also a basic prerequisite for excellent results.
In addition, restrictions on the rights of executable tools and clearly defined working environments (sandboxes) can help to control the potential impact. Regular snapshots of the generated results in a git are advisable for a structured rollback to previous states.
The more freedom an agent has, the more uncontrollable errors can sometimes be if it takes a wrong turn somewhere due to incorrect assumptions (Agentic Drift). Therefore, checking the results is an important control tool for the user. In the field of coding, pull requests (PRs) and the associated code reviews are already established workflows for structuring basic work steps in larger projects.
Some of these steps are already being automated by agents with specific skills. Why trust one agent when a second agent can monitor them?
This brings us to the next phase of AI evolution in 2026.
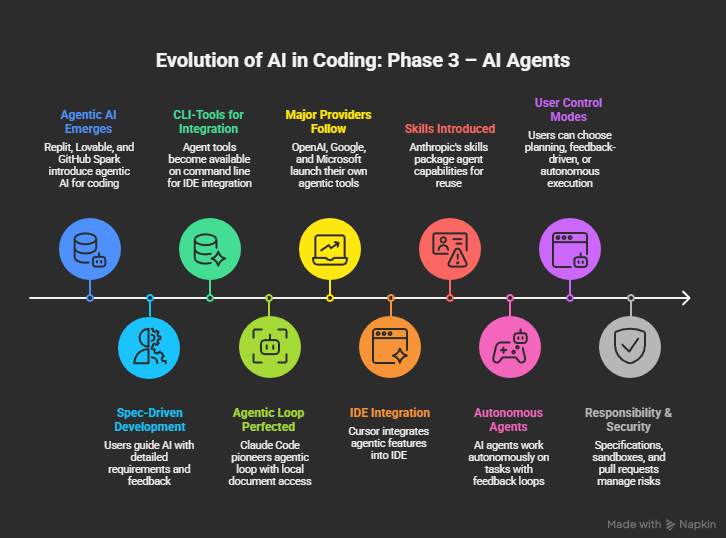
Phase 4 – Agent Orchestration
New concepts such as “Ralph Wiggum” or “Gastown” are examples of a further optimization stage in context engineering. While “Ralph” aims more at improving the verification criteria and “learning from mistakes” capabilities of the process, “Gastown” takes a different approach. Here, numerous instances are simply assigned the same task in parallel, and at the end, an arbitrator decides who has found the better solution. It’s a kind of competition for the best solution for the given goal. An additional refinement consists of breaking down the solution path into smaller steps in advance, which build on each other in a meaningful way. Once the first building blocks for the solution path are in place, other agents can build on them and thus complete more complex tasks in a meaningful way. This opens up an option for more parallel processing, because subtasks are completed autonomously.
The catch: these strategies come with a price tag. Because trials are repeated multiple times or carried out in parallel by several agents, more and more tokens are consumed. More and more computing power is required, and energy consumption increases.
At the same time, execution time increases. The autonomous agents sometimes work for hours or days to solve a task. However, this is not a bug but a feature, because the tasks that can be solved using these methods are now correspondingly large and complex. Some remarkable successes are now making the rounds. For example, in a demo project, Cursor developed a complete browser engine with millions of lines of code from scratch in just a few days. Claude Cowork, a new product from Anthropic, was also developed by Claude Code within a few days. These are results that would have been completely unthinkable just 1-2 years ago.
The current hype surrounding “Clawdbot” — now renamed first to “Moltbot” and now to “OpenClaw” — is fueled by the ingredients described above. OpenClaw has refined and further expanded the orchestration strategies. The bot is able to dynamically reload additional skills and generate new ones. It also has a persistent memory and thus learns to focus on specific things over time. Through daily loops, it retrieves new context from the internet and interacts proactively with its user. As soon as the user delegates tasks to it, the bot acts autonomously and also interacts with external persons, external knowledge sources, and other bots. A dedicated bot forum called “Moltbook” is currently causing a stir because it serves exclusively as a place for autonomous bots to exchange information and share their experience and knowledge with each other. This is also a type of context engineering pattern, but one that goes far beyond the previous conceptual limitations of local agents.
Update: “Antfarm” is a new open source tool that combines the approaches of “Ralph” and “Gastown” in a flexibly configurable framework and can be easily installed on “OpenClaw.” It promises to “build an agent team with one command” that can develop software completely autonomously.
Insights & Success factors
Looking back at the development of AI tools and their underlying patterns, several critical success factors can be identified. These are not so much individual features of AI tools, but rather general strategies on a more abstract level.
These can be broken down into the following factors:
- Context
- Code
- Loops
Better context and code
A key success factor is always finely granulated context, which is organized hierarchically and delivered dynamically to the language model at runtime. This is enriched by code that is also generated at runtime, which serves to find short cuts, create reliable tools, and add further context from external sources.
This takes context engineering to a whole new level:
- Input = language, code, and data
- Output = language, code, and data
The boundaries between code and language are becoming increasingly blurred. A bon mot from Andrej Karpathy] describes it as follows: “The hottest new programming language is English”
Users provide instructions in the form of goals and success criteria. Agents act autonomously in swarms and control and correct themselves independently until the specified goal is achieved.
More complex patterns
The complexity of the patterns has evolved from simple, static over dynamic to chaotic implementation steps. A paradox here is that
the simpler the input patterns at the beginning of AI evolution, the more unpredictable the results (hallucinations) were.
The more chaotic the input patterns at the advanced stage, the more deterministic the results appear. This is because, in the sum of actions across many loops, a clear goal is pursued and divergent results can thus be smoothed iteratively.
Another pattern is becoming apparent here. Whereas initially the instructions for LLMs consisted of simple text prompts, they now consist of hierarchically organized instructions made up of text and code, which are processed in multiple nested loops.
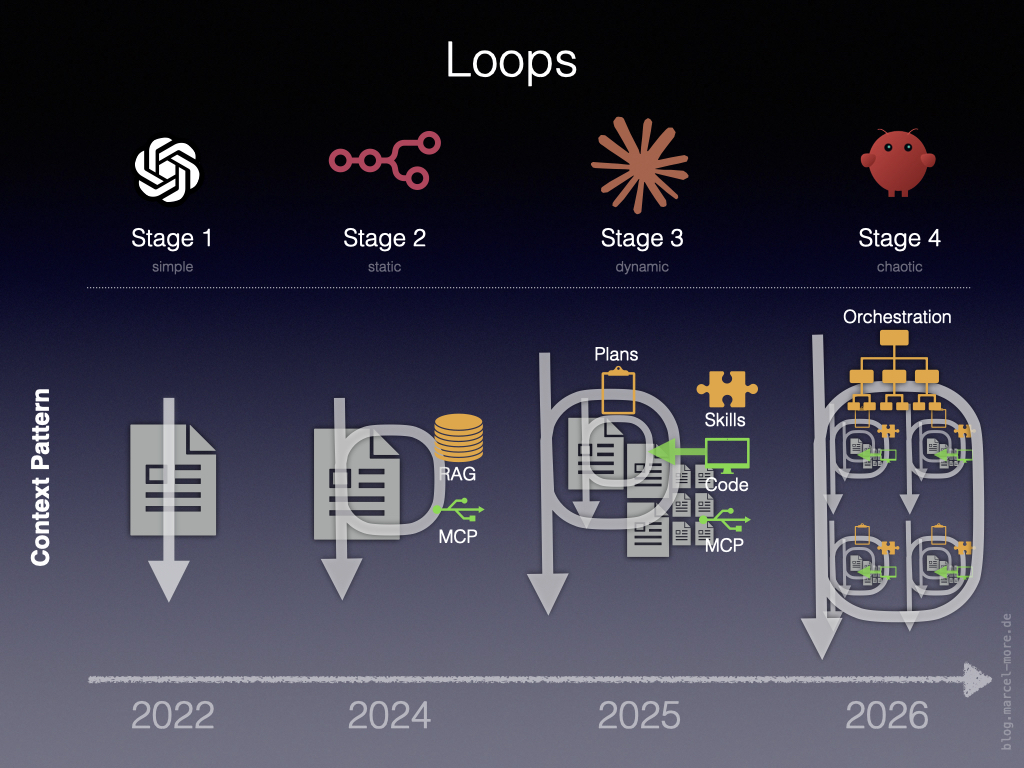
Hula hoop – loop by loop
Each stage of evolution added another level of looping.
- Level 1-2: Reasoning Loop
- Level 2-3: Agentic Loop
- Level 3-4: Ralph Loop / Orchestration Loop
These loops are nested within each other and serve to gradually consolidate the essentially unpredictable results of the LLM toward a defined target state.
The pattern builds directly on refined context engineering strategies. The ability to generate code dynamically at runtime makes it possible to compare context snippets deterministically with intermediate results and control the entire process in sub-steps.
In addition, there are other patterns such as debating, shuffling, and goal matching to break the risk of deadlocked loops and introduce sufficient variance into the overall process. Early agentic loops tended to produce repetitive errors when wrong decisions were made. These effects can be minimized through better strategies at the orchestration level.
Modern bots such as OpenClaw add additional loops beyond the actual tasks with Heartbeat. This is essentially an idle state for the agent, which keeps it ready for action at all times, even without user interaction.
There are also new concepts at the model level, such as Recursive Language Models, which enable the model to process context more efficiently. Recursion is, so to speak, a conditional loop that allows the model to find an optimal route in advance, even through extensive context sets.

Conclusion
First, it is important to understand that this development was only possible in a logical sequence. Each stage builds on the successes and failures of the previous stage. This leads to progress, but also to a lot of contradictions.
This becomes clear in debates or backward-looking studies, some of which fundamentally question the usefulness of AI applications based on results obtained at an earlier stage. Added to this is the rapid development in the entire field of AI, accompanied by many individual concepts and buzzwords, which on the one hand make it difficult to maintain an overview and gain an understanding of individual approaches. On the other hand, this also presents an obstacle to communicating about it in clear language with uniform meanings.
It is therefore helpful to detach yourself from the view of individual providers, tools, or features and try to look at things on a more abstract level.
What becomes clear here, among other things, is the ever-increasing refinement of strategies on the one hand. On the other hand, however, there is also the increasing complexity and rising consumption of resources required to ultimately solve problems that often appear simple. It is important to distinguish between the types of tasks assigned to AI and the strategy and effort required to potentially solve them. This is often still a dilemma — using a sledgehammer to crack a nut makes no sense if the result comes at a high price. On the other hand, we are increasingly moving into areas of activity that seem difficult or impossible to solve without the help of AI.
If one thinks further about the conclusions described above, the question inevitably arises as to what might come next.
The next level
It stands to reason that increasing complexity will also give rise to new problems. It could therefore be helpful to recombine the insights already gained and strategies already identified in a next stage. The aim would be to reduce complexity and establish simple patterns that support and reinforce each other.
We have already established that more and more nested loops produce an increasingly better focus under the conditions mentioned. What would happen if we generalized this approach? Not simply adding another loop with a new pattern on top, but incorporating an endless loop as a basic principle into the entire process.
We have also found that context provision and the agent loop are closely related. An important interaction is the gradual enrichment of context by tools in the form of code. The current bridge for this is skills, which provide agent prompts packaged with tools and data sources. From this perspective, skills are just another source of context. A memory in the form of all previous inputs and outputs is also a form of context, but with a higher weighting because it encodes the user’s goals and experiences.
The more efficient management of both active context for a task and passive context in the form of stored memories is a key task that needs to be addressed.
Although LLMs have been given increasingly larger context windows, there are still fundamental limitations to this approach. One solution lies in the agent loop, which ensures that the limited context windows are constantly filled from scratch with new, finely granulated subtasks. Orchestrating these subtasks requires goals, plans, and comparison criteria, which are also incorporated into the overall system as context.
This brings us closer to a structure that inherently combines all these ingredients. When instructions, knowledge, memory, and solution strategies all become part of the same context set, there is a chance that this system will organize itself, learn, and potentially gain new insights with each additional loop.
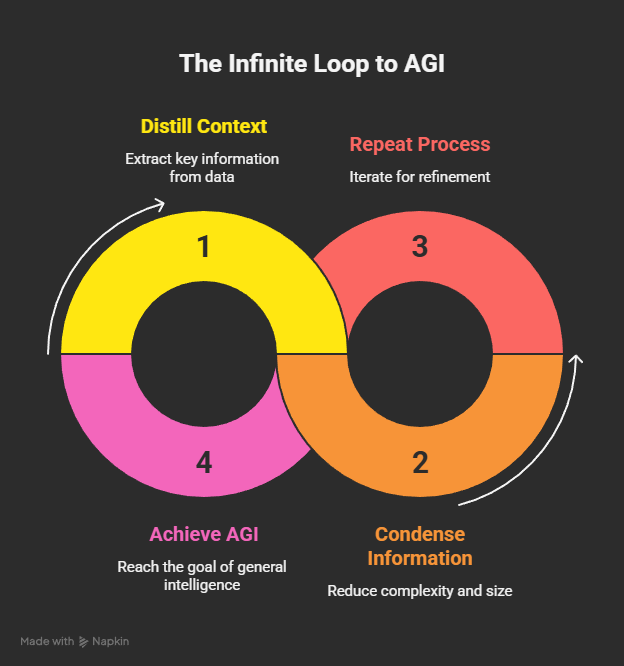
Infinite Loop
The following diagram shows the aforementioned ingredients arranged in an inherent system.
The architecture is based on the following elements:
Outer circle = Data & Knowledge
This is where classic context processing takes place, including the connection of data sources. In other words, what prompts, skills, MCPs, and APIs have been doing up to now.
Inner circle = persistent memory
This is where an additional context layer comes into play, containing a persistent layer of memories about past interactions, explicitly anchored knowledge, and meta-information for controlling processing.
Agent loop = connects LLMs, code, memory with context
The agent loop corresponds to the processing loop for specific tasks, as described previously in step 3. The agent uses code to optimize the processing process and execute new actions.
Heartbeat loop = outer loop
The outer loop keeps the system running. In addition to continuously triggering the agent loop, it supplies the context with new input, output, and external data, thereby enriching the system’s knowledge. Input via sensors (enabling the system to detect its own state and that of its environment) and updates via new world knowledge (which has previously been made available through LLM training) would also be conceivable.
All of this is combined with the ability to rearrange things and forget outdated context so that the system can continue to develop in a healthy way.
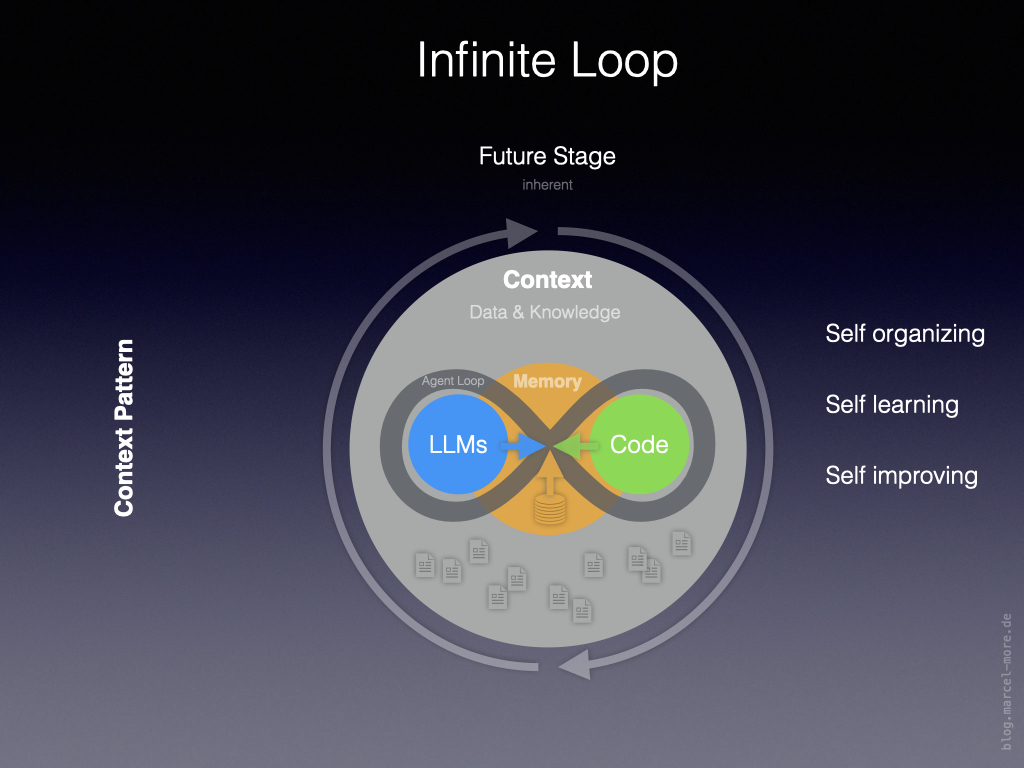
Although I cannot say how such a system could be built in concrete terms, it is conceivable that, with the characteristics described, it would be capable of reaching a new level of the AI evolution described above.
Epilogue
Perhaps it is an infinite loop that leads us to general artificial intelligence (AGI)? An infinite stream of context that is distilled and condensed in infinite repetitions until the result is achieved.
What will be the end result…
42 ?
Perhaps we will have used up an infinite number of tokens and all the energy in the world to calculate this.
Never mind — let’s find out!